
Pipeline
Also known as
- Chain of Operations
- Processing Pipeline
Intent
The Pipeline design pattern is intended to allow data processing in discrete stages, where each stage is represented by a different component and the output of one stage serves as the input for the next.
Explanation
The Pipeline pattern uses ordered stages to process a sequence of input values. Each implemented task is represented by a stage of the pipeline. You can think of pipelines as similar to assembly lines in a factory, where each item in the assembly line is constructed in stages. The partially assembled item is passed from one assembly stage to another. The outputs of the assembly line occur in the same order as that of the inputs.
Real world example
A real-world analogous example of the Pipeline design pattern is an assembly line in a car manufacturing plant.
In this analogy, the car manufacturing process is divided into several discrete stages, each stage handling a specific part of the car assembly. For example:
- Chassis Assembly: The base frame of the car is assembled.
- Engine Installation: The engine is installed onto the chassis.
- Painting: The car is painted.
- Interior Assembly: The interior, including seats and dashboard, is installed.
- Quality Control: The finished car is inspected for defects.
Each stage operates independently and sequentially, where the output of one stage (e.g., a partially assembled car) becomes the input for the next stage. This modular approach allows for easy maintenance, scalability (e.g., adding more workers to a stage), and flexibility (e.g., replacing a stage with a more advanced version). Just like in a software pipeline, changes in one stage do not affect the others, facilitating continuous improvements and efficient production.
In plain words
Pipeline pattern is an assembly line where partial results are passed from one stage to another.
Wikipedia says
In software engineering, a pipeline consists of a chain of processing elements (processes, threads, coroutines, functions, etc.), arranged so that the output of each element is the input of the next; the name is by analogy to a physical pipeline.
Programmatic Example
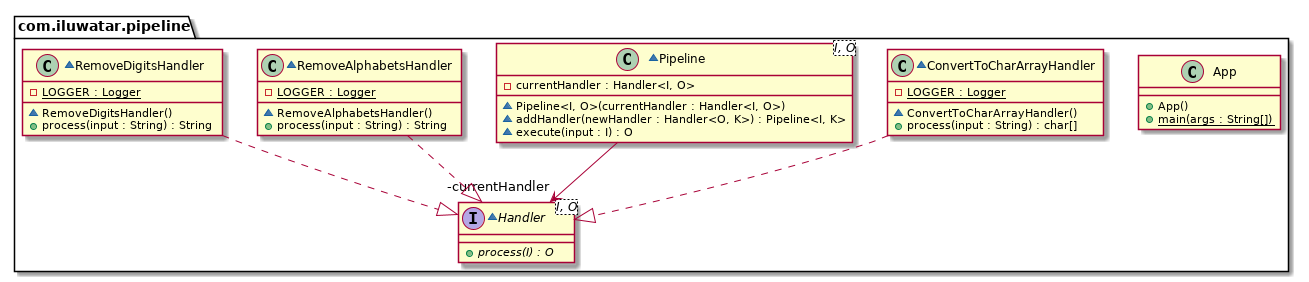
Let's create a string processing pipeline example. The stages of our pipeline are called Handlers.
interface Handler<I, O> {
O process(I input);
}
In our string processing example we have 3 different concrete Handlers.
class RemoveAlphabetsHandler implements Handler<String, String> {
// ...
}
class RemoveDigitsHandler implements Handler<String, String> {
// ...
}
class ConvertToCharArrayHandler implements Handler<String, char[]> {
// ...
}
Here is the Pipeline that will gather and execute the handlers one by one.
class Pipeline<I, O> {
private final Handler<I, O> currentHandler;
Pipeline(Handler<I, O> currentHandler) {
this.currentHandler = currentHandler;
}
<K> Pipeline<I, K> addHandler(Handler<O, K> newHandler) {
return new Pipeline<>(input -> newHandler.process(currentHandler.process(input)));
}
O execute(I input) {
return currentHandler.process(input);
}
}
And here's the Pipeline in action processing the string.
var filters = new Pipeline<>(new RemoveAlphabetsHandler()).addHandler(new RemoveDigitsHandler()).addHandler(new ConvertToCharArrayHandler());
filters.execute("GoYankees123!");
Class diagram
Applicability
Use the Pipeline pattern when you want to
- When you need to process data in a sequence of stages.
- When each stage of processing is independent and can be easily replaced or reordered.
- When you want to improve the scalability and maintainability of data processing code.
Tutorials
Known Uses
- Data transformation and ETL (Extract, Transform, Load) processes.
- Compilers for processing source code through various stages such as lexical analysis, syntax analysis, semantic analysis, and code generation.
- Image processing applications where multiple filters are applied sequentially.
- Logging frameworks where messages pass through multiple handlers for formatting, filtering, and output.
Consequences
Benefits:
- Decoupling: Each stage of the pipeline is a separate component, making the system more modular and easier to maintain.
- Reusability: Individual stages can be reused in different pipelines.
- Extensibility: New stages can be added without modifying existing ones.
- Scalability: Pipelines can be parallelized by running different stages on different processors or threads.
Trade-offs:
- Complexity: Managing the flow of data through multiple stages can introduce complexity.
- Performance Overhead: Each stage introduces some performance overhead due to context switching and data transfer between stages.
- Debugging Difficulty: Debugging pipelines can be more challenging since the data flows through multiple components.
Related Patterns
- Chain of Responsibility: Both patterns involve passing data through a series of handlers, but in Chain of Responsibility, handlers can decide not to pass the data further.
- Decorator: Both patterns involve adding behavior dynamically, but Decorator wraps additional behavior around objects, whereas Pipeline processes data in discrete steps.
- Composite: Like Pipeline, Composite also involves hierarchical processing, but Composite is more about part-whole hierarchies.